Dans cette première partie de ma plongée dans ce nouvel eldorado qu’on appelle l’AGI — une intelligence artificielle censée atteindre le même niveau que celui d’un être humain —, j’avais envie de revenir un peu aux bases. Notamment sur l’histoire des réseaux de neurones, qui sont aujourd’hui au cœur de nombreuses applications grand public d’IA que nous utilisons : assistants vocaux, moteurs de recommandation, outils de génération de texte ou d’image… tout part de là.
Un exemple simple pour comprendre les réseaux de neurones
J’ai toujours trouvé que cet exemple était une bonne façon d’expliquer ce qu’est un réseau de neurones. Il a un but précis facilement compréhensible.
Imaginez une entreprise qui a accumulé beaucoup de données sur ses anciens prospects. Elle aimerait maintenant utiliser l’intelligence artificielle pour mieux savoir, à l’avance, si un nouveau prospect a des chances de devenir client.
Pour ça, on peut reprendre les informations disponibles : le secteur d’activité du prospect, sa taille, son chiffre d’affaires, le nombre de rendez-vous réalisés… Et comme ce sont des anciennes fiches, on sait si le prospect est devenu client.
Le réseau de neurones va analyser toutes ces données et essayer de comprendre ce qui, en général, fait qu’un prospect devient client. Une fois le modèle entraîné, on pourra l’utiliser pour chaque nouveau prospect, et obtenir une estimation des chances de vente.
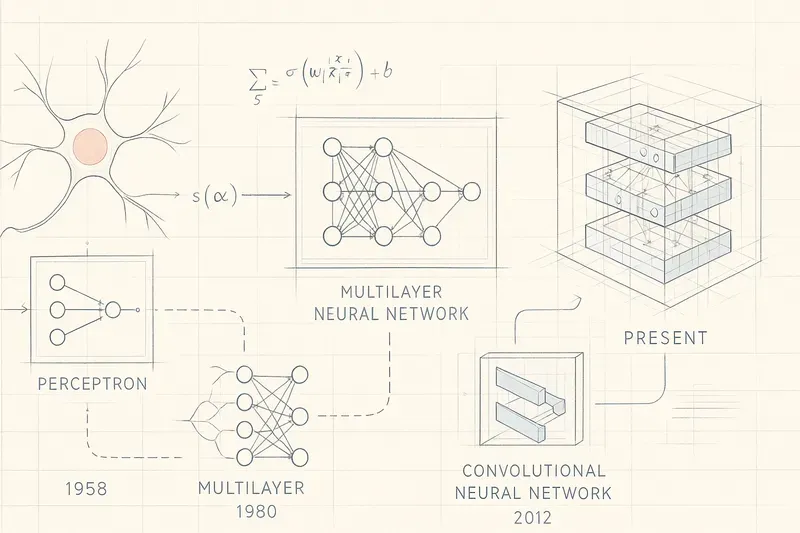
Les grandes étapes de l’histoire des réseaux de neurones
Voici les principales étapes historiques qui ont permis d’en arriver là :
- 1943 : McCulloch et Pitts imaginent pour la première fois un neurone artificiel, jetant les bases théoriques des réseaux de neurones.
- Années 50 : Frank Rosenblatt crée le perceptron, le premier réseau de neurones fonctionnel capable d’apprendre.
- 1970 - 1986 : Les bases mathématiques de la rétropropagation, formalisées par Seppo Linnainmaa (1970), ont conduit à l’introduction de l’algorithme par Paul Werbos (1974) et à sa popularisation comme méthode d’apprentissage clé des réseaux de neurones multicouches par Rumelhart, Hinton et Williams (1986).
- 1989 : Première utilisation à grande échelle dans le monde réel : la United States Postal Service s’appuie sur un réseau de neurones pour automatiser la lecture de chèques manuscrits.
Il existe bien d’autres étapes importantes après celles-ci, mais ces faits marquent, selon moi, les origines fondamentales de la technologie. Et le constat est frappant : si l’on considère le début de l’ère actuelle de l’IA comme la sortie publique de ChatGPT 3.0 en 2022, il aura fallu près de 80 ans pour qu’une vision scientifique assez claire devienne un outil grand public, utilisé quotidiennement par des millions de personnes.
Les limites des prédictions d’un réseau de neurones
Certains d’entre vous l’auront sans doute remarqué : l’exemple d’utilisation d’un réseau de neurones que j’ai présenté soulève plusieurs limites. Même si le modèle fournit une probabilité mathématiquement rigoureuse, cela ne signifie pas que la prédiction se réalisera forcément dans la réalité.
En effet, la conclusion d’une vente dépend de nombreux facteurs difficilement mesurables ou absents des données : le positionnement de l’entreprise sur son marché, le contexte économique local ou international, ou encore la qualité de la relation humaine entre le commercial et l’acheteur. Tous ces éléments peuvent influencer la décision finale, sans apparaître dans le modèle.
Le langage, un terrain de jeu plus stable
Le but serait donc, idéalement, de trouver un domaine où les prédictions seraient plus fiables.
Un de ces domaines est le langage, les LLM (Large Language Models), qui se concentrent sur une tâche bien précise : prédire le mot suivant à partir d’un texte donné et de son contexte. Cet objectif, en apparence plus simple que celui de prédire la conclusion d’une vente, présente un avantage majeur : il est plus stable, plus constant, et surtout plus universel.
Et c’est précisément cette simplicité qui fait leur force : ces modèles parviennent à comprendre le sens des questions, à saisir le contexte fourni, et à formuler des réponses cohérentes et adaptées, comme s’ils raisonnaient — alors qu’ils se contentent de poursuivre une phrase de façon statistiquement plausible.
Une continuité dans les principes fondamentaux
Ce qui m’interpelle dans toute cette histoire, c’est à quel point les principes théoriques initiaux — que ce soit pour les réseaux de neurones ou les modèles génératifs — ont été à la fois clairs, précis et étonnamment durables. On se rend compte aussi que, malgré l’effet de magie, les objectifs de ces technologies restent relativement simples : prédire un mot, une image, un comportement… Et pourtant, ces systèmes, une fois mis à l’échelle, deviennent capables de performances qui nous dépassent sur certains points.
Et maintenant, cap sur l’AGI
La prochaine étape annoncée est l’AGI, ou Artificial General Intelligence — une intelligence artificielle générale, c’est-à-dire capable de comprendre, apprendre et raisonner de façon large, flexible, et transversale… comme un humain.
Alors, où en est-on aujourd’hui ? Existe-t-il déjà des bases scientifiques solides pour l’AGI ? Quels sont les principes théoriques que les chercheurs explorent ? A-t-on une vision claire de cette révolution, ou navigue-t-on encore à vue ?
C’est ce que nous allons explorer dans la deuxième partie.