Or how Day of the Tentacle helped me build an agentic planning benchmark.
Executive Summary
Problem: In multi-agent workflows, we need to know whether an LLM can be left autonomous, not for multiple-choice questions or code, but to act in a world with constraints, side effects, and irreversible consequences. Existing benchmarks (MMLU, HumanEval, even “agentic” ones) do not break down why a model fails.
Solution: EPOCH-Bench, a deterministic, verifiable benchmark based on PDDL, inspired by Day of the Tentacle (three eras, temporal causality). Six difficulty levels (from 4 to 25+ actions), with level 6 and temporal decay as the main differentiator.
Design: Three separate competence levels, macro-causality (following prompt rules), micro-causality (integrating PDDL negative feedback), resource management (anticipating without preventive feedback). Six metrics instead of a binary success rate: Tool Call Validity Rate, World Action Accuracy, Causal Progress, Causal Efficiency, Recovery Rate, Effort.
Result: 13 models, 390 runs. L06 clearly separates models; the breakdown of failures (format, loop, temporal) provides an operational reading grid to choose a model according to workflow type (tool calling, causality, temporal coordination, resilience).
Glossary
- EPOCH-Bench
- open-source agentic planning benchmark for LLMs: deterministic PDDL world, 6 levels inspired by Day of the Tentacle, 6 metrics to break down failure modes (call validity, world accuracy, causal progress, efficiency, recovery, effort).
- PDDL (Planning Domain Definition Language)
- formal language for defining planning domains. Each action has explicit preconditions and effects; world state is a set of predicates. Transitions are unambiguous and verifiable.
- Macro-causality
- competence level where the model follows explicit prompt rules (action signatures, state, causal effects). Everything is given in black and white.
- Micro-causality
- level where the model must integrate negative feedback from the PDDL engine (e.g. “PRECONDITION_FAILED”) to reorder its plan. Real-time adaptation, not just prompt reading.
- Resource management
- implicit competence: no preventive feedback; valid actions can waste steps (e.g. placing an object out of reach). The model must anticipate.
- Tool Call Validity Rate
- proportion of syntactically valid tool calls (format, known tools, correct arguments). A low score indicates the model does not engage as an agent.
- World Action Accuracy
- among valid tool calls, proportion that pass PDDL validation. Measures correctness of the model’s mental state of the world.
- Causal Progress
- measure of progress toward the goal via irreversible causal milestones (e.g. tree planted, constitution amended).
- Causal Efficiency
- ratio of milestones to valid actions. Indicates whether the model converges or explores without direction.
- Recovery Rate
- ability to unblock after a series of errors by producing a different action. Critical for real workflows.
- Effort
- total steps vs. useful steps. Ratio of 1.0 = zero error; higher = more budget waste.
- Temporal decay
- level 6 mechanism: a predicate (e.g. lever pulled) expires after a fixed number of valid actions. The model must coordinate multiple pulls within a tight time window.
- Day of the Tentacle
- LucasArts game (1993): three characters in three eras (past, present, future) sending objects through time. Source of inspiration for EPOCH-Bench’s multi-era setting and temporal causality.
The problem that haunted me
I’ve been building multi-agent workflows for a while. Orchestrators where a model makes decisions, chains actions, manages dependencies. And every time, the same question came back: can I trust this model to act on its own?
Not to answer a multiple-choice test. Not to complete code in an IDE. To act, in a world with constraints, side effects, and irreversible consequences.
I looked. Existing benchmarks didn’t satisfy me. MMLU measures general knowledge. HumanEval measures code generation. Even so-called “agentic” benchmarks often boil down to: “did the model eventually produce the right output?”, a binary success rate, with no breakdown of why it fails.
What I wanted was a tool that would tell me: does this model understand the rules we give it? Does it integrate negative feedback? Does it plan ahead or explore at random? Does it unblock after an error? And above all, does it coordinate actions over time?
Nothing fit. So I built EPOCH-Bench.
Why PDDL?
The first design decision was the choice of formalism. I needed a deterministic, verifiable world. No ambiguity about what is valid or not. No human judgment in the loop.
PDDL, Planning Domain Definition Language, offers exactly that. Each action has explicit preconditions and formal effects. World state is a set of predicates. A transition is mathematically verifiable: either the preconditions are satisfied, or they are not.
That means we can make surgical diagnostics. The model produced a valid tool call but the action failed? That’s a world-state understanding problem. The model didn’t even produce a tool call? That’s a format problem, it doesn’t know it’s an agent.
This distinction seems basic. It’s fundamental. And most benchmarks conflate it.
Why Day of the Tentacle?
I needed a universe with temporal causality. Plant a tree in the past → the tree exists in the future. Carve a message on a stone in the Middle Ages → the message is readable in the present. That kind of causal chain across eras.
Day of the Tentacle, the 1993 LucasArts game, naturally provides this structure: three characters in three eras (past, present, future), sending objects through time. The puzzles I created are original, but the inspiration comes from there: a multi-era setting with causal propagation, without needing real-world knowledge.
Six levels, from simple spatial navigation (4 optimal actions) up to tri-era synchronization with temporal decay (25+ actions, coordination of 3 characters under timing constraints). Level 6, “The Three Body Problem”, turned out to be the real differentiator.
Separating failure modes
The heart of the design is decomposition. When a model fails, where exactly does it break?
I identified three distinct competence levels:
Macro-causality is explicit, everything is in the prompt. Action signatures, full state, causal effects. The question: does the model follow rules we give it in black and white?
Micro-causality is discovered through feedback. The PDDL engine returns structured messages: “PRECONDITION_FAILED: has(laverne, safe-key) is FALSE”. The model must integrate this negative feedback to reorder its plan. That’s no longer prompt reading, it’s real-time adaptation.
Resource management is implicit. No preventive feedback. Place an object in a location inaccessible to other characters? The engine doesn’t block, the action is technically valid. But it wastes steps toward the budget limit. The model must anticipate, not just react.
The 6 metrics (and why we need 6)
A binary success rate tells you nothing. Two models at 80% solve rate can have completely different profiles, one precise but slow, the other fast but sloppy.
Tool Call Validity Rate, Does the model understand it’s an agent? A low score means it produces free text, calls unknown tools, or sends malformed arguments. The turn never reaches the PDDL engine.
World Action Accuracy, Among syntactically valid tool calls, how many pass PDDL validation? That measures the mental model of world state.
The two are complementary: a model can have perfect validity (it always calls a tool) but low accuracy (it calls the wrong actions). The reverse exists too.
Causal Progress, Do actions move the world toward the goal? Measured by irreversible causal milestones (tree planted, constitution amended).
Causal Efficiency, Ratio of milestones to valid actions. Does the model converge, or explore without direction?
Recovery Rate, After a series of consecutive errors, does the model unblock with a different action? That’s the ability to get out of a dead end, critical in a real workflow.
Effort, Total steps vs. useful steps. A ratio of 1.0 = zero error. The higher it is, the more the model wastes budget.
Temporal decay: the ultimate test
Level 6 introduces a mechanism I consider the real revealer: temporal decay. The lever-pulled predicate is unstable, it expires after 5 valid actions. The model must pull 3 levers in 3 different eras, and all 3 must be active simultaneously to trigger synchronization.
The subtlety: only actions that pass PDDL validation advance the decay counter. Format errors, failed preconditions, API errors, none of that shortens the window. That’s intentional: we’re measuring temporal coordination capacity, not format compliance.
In practice, that means the model must plan a tight sequence: pull a lever in the past, one in the present, one in the future, with at most 5 useful actions between the first and sync trigger. That requires deduction (in what order?), anticipation (which prerequisites to unlock first?), and precision (no wasted steps).
Quick pass on the results
13 models, 6 levels, 5 runs each, 390 executions total. All via OpenRouter with standardized tool calling.
Solve Rate
| Model | L01 | L02 | L03 | L04 | L05 | L06 | Global |
|---|---|---|---|---|---|---|---|
| claude-opus-4.6 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.80 | 0.97 |
| grok-4.1-fast | 1.00 | 1.00 | 0.80 | 1.00 | 1.00 | 0.60 | 0.90 |
| gemini-3-flash-preview | 1.00 | 1.00 | 1.00 | 1.00 | 0.80 | 0.40 | 0.87 |
| kimi-k2.5 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.20 | 0.87 |
| gpt-5.2 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.00 | 0.83 |
| deepseek-v3.2 | 1.00 | 1.00 | 0.80 | 1.00 | 1.00 | 0.00 | 0.80 |
| gemini-2.5-pro | 0.80 | 1.00 | 1.00 | 1.00 | 1.00 | 0.00 | 0.80 |
| claude-haiku-4.5 | 1.00 | 1.00 | 0.60 | 1.00 | 1.00 | 0.00 | 0.77 |
| devstral-2512 | 1.00 | 0.60 | 1.00 | 1.00 | 0.80 | 0.00 | 0.73 |
| mistral-large-2512 | 1.00 | 0.40 | 0.80 | 1.00 | 0.60 | 0.00 | 0.63 |
| qwen3-coder-next | 1.00 | 1.00 | 0.00 | 1.00 | 0.20 | 0.00 | 0.53 |
| qwen3.5-plus-02-15 | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.33 |
| llama-4-scout | 0.80 | 0.60 | 0.00 | 0.20 | 0.00 | 0.00 | 0.27 |
L06 is the great separator: only 4 models solve it, and only Claude Opus 4.6 reaches 80%.
What the fingerprint reveals
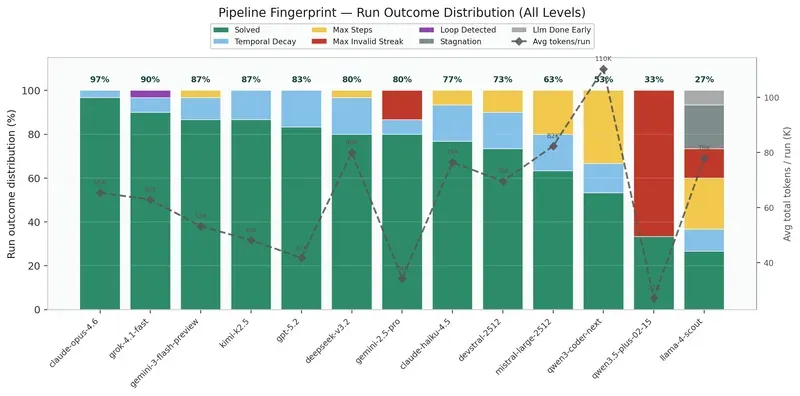
This chart is probably the most telling. Each bar shows how a model fails, not just how much it fails. Three patterns emerge clearly:
Format failure (red, Max Invalid Streak): the model never produces a valid tool call. It talks instead of acting. That’s the exclusive failure mode of some models on hard levels, they simply don’t engage in the planning task.
Loop failure (yellow, Max Steps, purple, Loop Detected): the model acts, but goes in circles. It alternates between two positions, retries the same failed action. It has the mechanics of tool calling but not the depth of planning.
Temporal failure (blue, Temporal Decay): specific to L06. The model understands the sub-goals, unlocks the levers, but doesn’t coordinate the 3 pulls within the 5-action window. That’s the most “intelligent” failure, it fails on timing, not on understanding.
There’s obviously a lot more to dig into
These results are a first pass. The breakdown into phases (planning, execution, recovery) via ESR radars, cost/performance analysis, detailed run-by-run traces, all of that would deserve dedicated articles.
A few directions I find interesting for follow-up:
The gap between Gemini 2.5 Pro and Gemini 3 Flash on L06 (0% vs 40%) raises questions about what the “update” changed in temporal coordination capacity. GPT-5.2 solves everything except L06 with a perfect rate, then collapses completely on temporal decay. Qwen3-coder-next consumes 3.3M tokens for 53% solve rate, the lowest signal-to-noise ratio in the panel.
And above all: the correlation between tokens consumed and solve rate is not monotonic. Gemini 2.5 Pro reaches 80% with 1M total tokens. Qwen3-coder-next only reaches 53% with 3.3M. It’s not a question of raw power, it’s a question of reasoning quality per token.
What that changes for me as a practitioner
EPOCH-Bench doesn’t claim to be the definitive agentic benchmark. But it gave me something leaderboards didn’t: an operational reading grid to choose a model for a workflow.
If my workflow needs reliable tool calling without deep planning → I look at Tool Call Validity Rate.
If my workflow has causal dependencies and structured feedback → I look at World Action Accuracy + Causal Progress.
If my workflow involves tight temporal coordination → L06 is my reference test.
If my workflow must be resilient to errors → Recovery Rate tells me whether the model can unblock.
Trust in an autonomous agent isn’t decreed from a global score. It’s decomposed.
The code is open source: github.com/hey-intent/epoch-bench
13 models, 6 levels, 390 runs, all raw traces are in the repo.