Ou comment Day of the Tentacle m’a aidé à construire un benchmark de planification agentique.
Résumé exécutif
Problème : Dans des workflows multi-agents, on doit savoir si un LLM peut être laissé autonome, pas pour un QCM ou du code, mais pour agir dans un monde avec contraintes, effets de bord et conséquences irréversibles. Les benchmarks existants (MMLU, HumanEval, voire « agentiques ») ne décomposent pas pourquoi un modèle échoue.
Solution : EPOCH-Bench, un benchmark déterministe et vérifiable basé sur PDDL, inspiré de Day of the Tentacle (trois époques, causalité temporelle). Six niveaux de difficulté (de 4 à 25+ actions), dont le niveau 6 avec décroissance temporelle comme discriminant principal.
Design : Trois niveaux de compétence séparés, macro-causalité (suivre les règles du prompt), micro-causalité (intégrer le feedback négatif PDDL), gestion de ressources (anticiper sans feedback préventif). Six métriques au lieu d’un taux de succès binaire : Tool Call Validity Rate, World Action Accuracy, Causal Progress, Causal Efficiency, Recovery Rate, Effort.
Résultat : 13 modèles, 390 runs. L06 sépare nettement les modèles ; la décomposition des échecs (format, boucle, temporel) donne une grille de lecture opérationnelle pour choisir un modèle selon le type de workflow (tool calling, causalité, coordination temporelle, résilience).
Glossaire
- EPOCH-Bench
- benchmark open source de planification agentique pour LLMs : monde PDDL déterministe, 6 niveaux inspirés de Day of the Tentacle, 6 métriques pour décomposer les modes d’échec (validité des appels, précision sur le monde, progrès causal, efficacité, récupération, effort).
- PDDL (Planning Domain Definition Language)
- langage formel de définition de domaines de planification. Chaque action a des préconditions et des effets explicites ; l’état du monde est un ensemble de prédicats. Les transitions sont vérifiables sans ambiguïté.
- Macro-causalité
- niveau de compétence où le modèle suit des règles explicites du prompt (signatures d’action, état, effets causaux). Tout est donné noir sur blanc.
- Micro-causalité
- niveau où le modèle doit intégrer le feedback négatif du moteur PDDL (ex. « PRECONDITION_FAILED ») pour réordonner son plan. Adaptation en temps réel, pas seulement lecture du prompt.
- Gestion de ressources
- compétence implicite : pas de feedback préventif ; des actions valides peuvent gaspiller des pas (ex. poser un objet hors de portée). Le modèle doit anticiper.
- Tool Call Validity Rate
- proportion d’appels d’outils syntaxiquement valides (format, outils connus, arguments corrects). Un score bas indique que le modèle ne s’engage pas comme agent.
- World Action Accuracy
- parmi les tool calls valides, proportion qui passent la validation PDDL. Mesure la justesse du modèle mental de l’état du monde.
- Causal Progress
- mesure du progrès vers le but via des jalons causaux irréversibles (ex. arbre planté, constitution amendée).
- Causal Efficiency
- ratio jalons / actions valides. Indique si le modèle converge ou explore sans direction.
- Recovery Rate
- capacité à se débloquer après une série d’erreurs en produisant une action différente. Critique pour les workflows réels.
- Effort
- steps totaux vs. steps utiles. Ratio 1.0 = zéro erreur ; plus élevé = plus de gaspillage de budget.
- Décroissance temporelle (temporal decay)
- mécanisme du niveau 6 : un prédicat (ex. levier tiré) expire après un nombre fixe d’actions valides. Le modèle doit coordonner plusieurs tirages dans une fenêtre temporelle serrée.
- Day of the Tentacle
- jeu LucasArts (1993) : trois personnages dans trois époques (passé, présent, futur) qui s’envoient des objets dans le temps. Source d’inspiration pour le cadre multi-époque et la causalité temporelle d’EPOCH-Bench.
Le problème qui me hantait
Je construis des workflows multi-agents depuis un moment. Des orchestrateurs où un modèle prend des décisions, enchaîne des actions, gère des dépendances. Et à chaque fois, la même question revenait : est-ce que je peux faire confiance à ce modèle pour agir seul ?
Pas pour répondre à un QCM. Pas pour compléter du code dans un IDE. Pour agir, dans un monde avec des contraintes, des effets de bord, et des conséquences irréversibles.
J’ai cherché. Les benchmarks existants ne me satisfaisaient pas. MMLU mesure de la culture générale. HumanEval mesure de la génération de code. Même les benchmarks dits “agentiques” se résument souvent à : “le modèle a-t-il fini par produire le bon output ?”, un taux de succès binaire, sans décomposition de pourquoi ça échoue.
Ce que je voulais, c’était un outil qui me dise : ce modèle comprend-il les règles qu’on lui donne ? Intègre-t-il le feedback négatif ? Planifie-t-il en avant ou explore-t-il au hasard ? Se débloque-t-il après une erreur ? Et surtout, est-ce qu’il coordonne des actions dans le temps ?
Rien ne correspondait. Alors j’ai construit EPOCH-Bench.
Pourquoi PDDL ?
La première décision de design a été le choix du formalisme. J’avais besoin d’un monde déterministe et vérifiable. Pas d’ambiguïté sur ce qui est valide ou non. Pas de jugement humain dans la boucle.
PDDL, Planning Domain Definition Language, offre exactement ça. Chaque action a des préconditions explicites et des effets formels. L’état du monde est un ensemble de prédicats. Une transition est mathématiquement vérifiable : soit les préconditions sont satisfaites, soit elles ne le sont pas.
Ça veut dire qu’on peut poser des diagnostics chirurgicaux. Le modèle a produit un tool call valide mais l’action a échoué ? C’est un problème de compréhension de l’état du monde. Le modèle n’a même pas produit de tool call ? C’est un problème de format, il ne sait pas qu’il est un agent.
Cette distinction semble basique. Elle est fondamentale. Et la plupart des benchmarks la confondent.
Pourquoi Day of the Tentacle ?
J’avais besoin d’un univers avec de la causalité temporelle. Planter un arbre dans le passé → l’arbre existe dans le futur. Graver un message sur une pierre au Moyen-Âge → le message est lisible au présent. Ce genre de chaînes causales qui traversent les époques.
Day of the Tentacle, le jeu LucasArts de 1993, fournit naturellement cette structure : trois personnages dans trois époques (passé, présent, futur), qui s’envoient des objets à travers le temps. Les puzzles que j’ai créés sont originaux, mais l’inspiration vient de là : un cadre multi-époque avec propagation causale, sans avoir besoin de connaissances du monde réel.
Six niveaux, de la navigation spatiale simple (4 actions optimales) jusqu’à la synchronisation tri-époque avec décroissance temporelle (25+ actions, coordination de 3 personnages sous contrainte de timing). Le niveau 6, “The Three Body Problem”, s’est avéré être le vrai discriminant.
Séparer les modes d’échec
Le cœur du design, c’est la décomposition. Quand un modèle échoue, où exactement ça casse ?
J’ai identifié trois niveaux de compétence distincts :
La macro-causalité est explicite, tout est dans le prompt. Les signatures d’action, l’état complet, les effets causaux. La question : le modèle suit-il des règles qu’on lui donne noir sur blanc ?
La micro-causalité est découverte par feedback. Le moteur PDDL renvoie des messages structurés : “PRECONDITION_FAILED: has(laverne, safe-key) is FALSE”. Le modèle doit intégrer ce feedback négatif pour réordonner son plan. Ce n’est plus de la lecture de prompt, c’est de l’adaptation en temps réel.
La gestion de ressources est implicite. Aucun feedback préventif. Poser un objet dans un lieu inaccessible aux autres personnages ? Le moteur ne bloque pas, l’action est techniquement valide. Mais elle gaspille des pas vers le budget limite. Le modèle doit anticiper, pas seulement réagir.
Les 6 métriques (et pourquoi il en faut 6)
Un taux de succès binaire ne raconte rien. Deux modèles à 80% de solve rate peuvent avoir des profils complètement différents, l’un est précis mais lent, l’autre est rapide mais brouillon.
Tool Call Validity Rate, Le modèle comprend-il qu’il est un agent ? Un score bas signifie qu’il produit du texte libre, appelle des outils inconnus, ou envoie des arguments malformés. Le tour n’atteint jamais le moteur PDDL.
World Action Accuracy, Parmi les tool calls syntaxiquement valides, combien passent la validation PDDL ? Ça mesure le modèle mental de l’état du monde.
Les deux sont complémentaires : un modèle peut avoir une validité parfaite (il appelle toujours un outil) mais une accuracy faible (il appelle les mauvaises actions). L’inverse existe aussi.
Causal Progress, Les actions font-elles avancer le monde vers le but ? Mesuré par des jalons causaux irréversibles (arbre planté, constitution amendée).
Causal Efficiency, Ratio jalons / actions valides. Le modèle converge-t-il, ou explore-t-il sans direction ?
Recovery Rate, Après une série d’erreurs consécutives, le modèle se débloque-t-il avec une action différente ? C’est la capacité à sortir d’une impasse, critique dans un workflow réel.
Effort, Steps totaux vs. steps utiles. Un ratio de 1.0 = zéro erreur. Plus c’est élevé, plus le modèle gaspille du budget.
Le temporal decay : le test ultime
Le niveau 6 introduit un mécanisme que je considère comme le vrai révélateur : la décroissance temporelle. Le prédicat lever-pulled est instable, il expire après 5 actions valides. Le modèle doit tirer 3 leviers dans 3 époques différentes, et les 3 doivent être actifs simultanément pour déclencher la synchronisation.
La subtilité : seules les actions qui passent la validation PDDL avancent le compteur de décroissance. Les erreurs de format, les préconditions échouées, les erreurs d’API, rien de tout ça ne raccourcit la fenêtre. C’est voulu : on mesure la capacité de coordination temporelle, pas la compliance de format.
En pratique, ça signifie que le modèle doit planifier une séquence serrée : tirer un levier dans le passé, un dans le présent, un dans le futur, avec au maximum 5 actions utiles entre le premier et le déclenchement de la synchro. Ça demande de la déduction (dans quel ordre ?), de l’anticipation (quels prérequis débloquer avant ?), et de la précision (pas de gaspillage de pas).
Passage rapide sur les résultats
13 modèles, 6 niveaux, 5 runs chacun, 390 exécutions au total. Tous via OpenRouter avec tool calling standardisé.
Solve Rate
| Modèle | L01 | L02 | L03 | L04 | L05 | L06 | Global |
|---|---|---|---|---|---|---|---|
| claude-opus-4.6 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.80 | 0.97 |
| grok-4.1-fast | 1.00 | 1.00 | 0.80 | 1.00 | 1.00 | 0.60 | 0.90 |
| gemini-3-flash-preview | 1.00 | 1.00 | 1.00 | 1.00 | 0.80 | 0.40 | 0.87 |
| kimi-k2.5 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.20 | 0.87 |
| gpt-5.2 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.00 | 0.83 |
| deepseek-v3.2 | 1.00 | 1.00 | 0.80 | 1.00 | 1.00 | 0.00 | 0.80 |
| gemini-2.5-pro | 0.80 | 1.00 | 1.00 | 1.00 | 1.00 | 0.00 | 0.80 |
| claude-haiku-4.5 | 1.00 | 1.00 | 0.60 | 1.00 | 1.00 | 0.00 | 0.77 |
| devstral-2512 | 1.00 | 0.60 | 1.00 | 1.00 | 0.80 | 0.00 | 0.73 |
| mistral-large-2512 | 1.00 | 0.40 | 0.80 | 1.00 | 0.60 | 0.00 | 0.63 |
| qwen3-coder-next | 1.00 | 1.00 | 0.00 | 1.00 | 0.20 | 0.00 | 0.53 |
| qwen3.5-plus-02-15 | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.33 |
| llama-4-scout | 0.80 | 0.60 | 0.00 | 0.20 | 0.00 | 0.00 | 0.27 |
L06 est le grand séparateur : seuls 4 modèles le résolvent, et seul Claude Opus 4.6 atteint 80%.
Ce que le fingerprint révèle
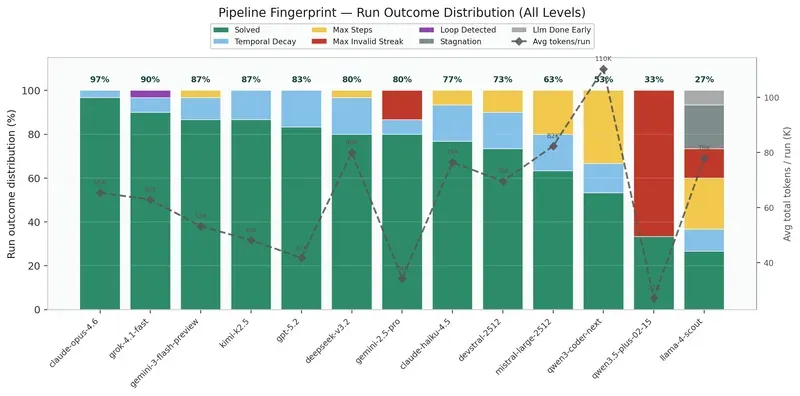
Ce graphique est probablement le plus parlant. Chaque barre montre comment un modèle échoue, pas juste combien il échoue. Trois patterns émergent clairement :
L’échec de format (rouge, Max Invalid Streak) : le modèle ne produit jamais de tool call valide. Il parle au lieu d’agir. C’est le mode d’échec exclusif de certains modèles sur les niveaux difficiles, ils ne s’engagent tout simplement pas dans la tâche de planification.
L’échec de boucle (jaune, Max Steps, violet, Loop Detected) : le modèle agit, mais tourne en rond. Il alterne entre deux positions, retente la même action échouée. Il a la mécanique du tool calling mais pas la profondeur de planification.
L’échec temporel (bleu, Temporal Decay) : spécifique à L06. Le modèle comprend les sous-objectifs, débloque les leviers, mais ne coordonne pas les 3 tirages dans la fenêtre de 5 actions. C’est l’échec le plus “intelligent”, il échoue sur le timing, pas sur la compréhension.
Il y a évidemment beaucoup à creuser
Ces résultats sont un premier passage. La décomposition en phases (planning, exécution, recovery) via les radars ESR, l’analyse coût/performance, les traces détaillées run par run, tout ça mériterait des articles dédiés.
Quelques pistes que je trouve intéressantes pour la suite :
L’écart entre Gemini 2.5 Pro et Gemini 3 Flash sur L06 (0% vs 40%) pose des questions sur ce que la “mise à jour” a changé dans la capacité de coordination temporelle. GPT-5.2 résout tout sauf L06 avec un taux parfait, puis s’effondre complètement sur la décroissance temporelle. Qwen3-coder-next consomme 3.3M tokens pour 53% de solve rate, le rapport signal/bruit le plus faible du panel.
Et surtout : la corrélation entre le nombre de tokens consommés et le solve rate n’est pas monotone. Gemini 2.5 Pro atteint 80% avec 1M tokens total. Qwen3-coder-next n’atteint que 53% avec 3.3M. Ce n’est pas une question de puissance brute, c’est une question de qualité de raisonnement par token.
Ce que ça change pour moi en tant que praticien
EPOCH-Bench ne prétend pas être le benchmark agentique définitif. Mais il m’a donné quelque chose que les leaderboards ne donnaient pas : une grille de lecture opérationnelle pour choisir un modèle dans un workflow.
Si mon workflow demande du tool calling fiable sans planification profonde → je regarde le Tool Call Validity Rate.
Si mon workflow a des dépendances causales et du feedback structuré → je regarde le World Action Accuracy + Causal Progress.
Si mon workflow implique de la coordination temporelle serrée → L06 est mon test de référence.
Si mon workflow doit être résilient aux erreurs → le Recovery Rate me dit si le modèle sait se débloquer.
La confiance dans un agent autonome, ça ne se décrète pas sur un score global. Ça se décompose.
Le code est open source : github.com/hey-intent/epoch-bench
13 modèles, 6 niveaux, 390 runs, toutes les traces brutes sont dans le repo.