Articles connexes : Recette LLM façon GPT : l’architecture expliquée | Les embeddings : comment l’IA fait des maths avec les mots
Résumé Exécutif
Cet article démystifie l’attention multi-head, mécanisme central des Transformers comme ChatGPT, à travers la métaphore de 8 projecteurs éclairant simultanément une phrase sous différents angles : syntaxe, pronoms, causalité, sémantique…
Le problème : Un seul mécanisme d’attention ne peut pas capturer simultanément toutes les relations multidimensionnelles du langage (grammaire, sens, références, logique). C’est comme essayer d’éclairer une scène complexe avec un seul projecteur.
La solution : L’attention multi-head utilise plusieurs “têtes” d’attention en parallèle (12 têtes pour GPT-2, jusqu’à 96 pour GPT-3, 32-64 pour LLaMA 2, ou 12 pour BERT-base). Chaque tête se spécialise spontanément pendant l’entraînement dans un type de relation linguistique spécifique, travaillant indépendamment comme des experts dans leur domaine.
Le résultat : Les représentations de chaque tête sont fusionnées pour créer une compréhension riche et multidimensionnelle. Par exemple, GPT-2 utilise 12 têtes, GPT-3 jusqu’à 96 têtes, permettant aux LLMs de “voir” votre message sous tous les angles simultanément.
Points clés :
- Traitement parallèle : toutes les têtes analysent simultanément, pas séquentiellement
- Spécialisation émergente : chaque tête découvre naturellement son domaine d’expertise
- Fusion intelligente : les résultats sont concaténés et harmonisés pour une compréhension complète
- Efficacité prouvée : plusieurs têtes spécialisées valent mieux qu’une seule tête très puissante
Cet article explique ces concepts avec des simplifications pédagogiques, tout en précisant les nuances techniques et en fournissant des ressources pour approfondir.
Glossaire : Comprendre les termes techniques
- Attention Multi-Head
- : Mécanisme central des Transformers utilisant plusieurs “têtes” d’attention en parallèle pour capturer simultanément différents types de relations linguistiques (syntaxe, sémantique, références, causalité, etc.). Chaque tête analyse la phrase sous un angle spécifique, puis les résultats sont fusionnés.
- Transformers
- : Architecture de réseau de neurones introduite en 2017 (papier “Attention Is All You Need”) qui repose sur le mécanisme d’attention au lieu des RNN/LSTM. Cette architecture est la base de tous les LLMs modernes comme GPT, Claude, Llama.
- QKV (Query/Key/Value)
- : Trois projections linéaires utilisées dans le calcul d’attention. Query (requête) : ce que chaque mot cherche comme information. Key (clé) : ce que chaque mot offre comme information aux autres. Value (valeur) : l’information concrète transmise par chaque mot. L’attention compare les Queries avec les Keys pour déterminer comment combiner les Values.
- Softmax
- : Fonction mathématique qui transforme les scores d’attention bruts en probabilités normalisées (sommant exactement à 1). Elle permet de convertir des scores numériques en poids d’attention interprétables.
- Têtes d’attention
- : Unités indépendantes dans le mécanisme multi-head. Chaque tête calcule sa propre attention en parallèle. Les dimensions varient selon les modèles (ex. 64 dimensions par tête pour un total de 512 avec 8 têtes). Les sorties de toutes les têtes sont concaténées puis transformées.
- LLM (Large Language Model)
- : Modèles de langage à grande échelle comme GPT-3/4, Claude, Llama, entraînés sur des milliards ou trillions de mots pour prédire et générer du texte. Ils utilisent l’architecture Transformer avec attention multi-head.
- Spécialisation émergente
- : Phénomène où chaque tête d’attention développe spontanément une expertise dans un type spécifique de relation linguistique (pronoms, syntaxe, entités nommées, etc.) pendant l’entraînement, sans instruction explicite.
- Concaténation
- : Opération qui met bout à bout les représentations de toutes les têtes d’attention pour créer une représentation enrichie et multidimensionnelle du texte.
Quand vous écrivez “La banque a refusé mon prêt parce qu’elle était trop prudente”, comment ChatGPT sait-il que “elle” désigne la banque et non vous ? Et comment comprend-il simultanément que “banque” est une institution financière, que “prudente” décrit cette institution, et que “parce qu’” introduit une explication ? Un seul mécanisme d’attention pourrait manquer ces nuances. C’est pourquoi les grands modèles de langage utilisent quelque chose de plus puissant.
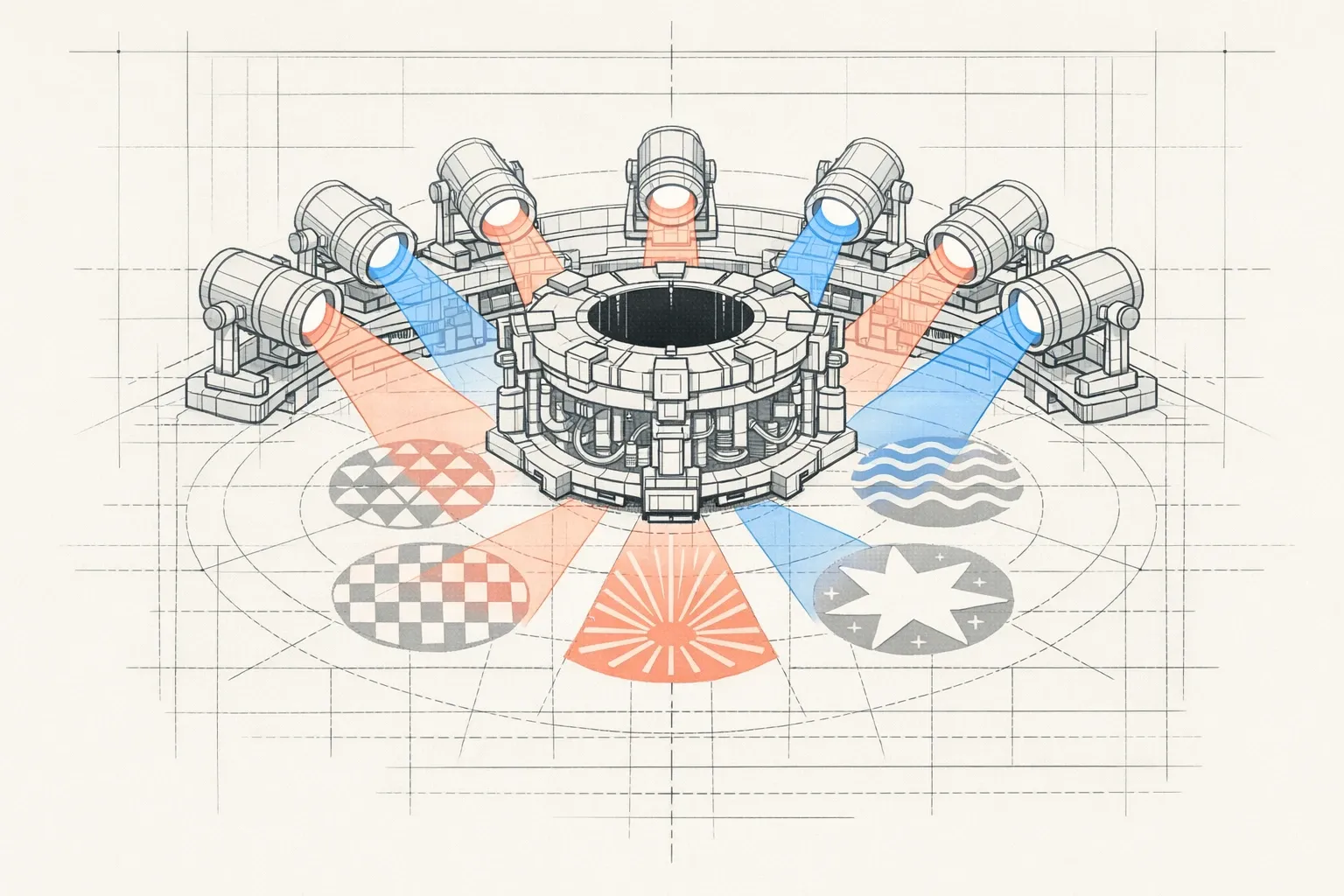
Imaginez une scène de crime plongée dans l’obscurité. Un seul projecteur pourrait éclairer les indices un par un, mais vous passeriez à côté de connexions cruciales. Maintenant, imaginez 8 projecteurs différents, chacun orienté selon un angle unique, révélant simultanément les empreintes au sol, les éclaboussures sur le mur, les reflets sur les surfaces métalliques, les ombres suspectes. C’est exactement ce que fait l’attention multi-head : elle illumine votre phrase sous plusieurs angles à la fois, chacun révélant un aspect différent du sens.
Le Problème Qu’Un Seul Projecteur Ne Peut Pas Résoudre
Reprenons notre phrase : “La banque a refusé mon prêt parce qu’elle était trop prudente.”
Un mécanisme d’attention simple (un seul projecteur) doit faire des choix difficiles. Il peut se concentrer sur :
- Les relations grammaticales : “elle” est le sujet de “était”
- Les liens de référence : “elle” renvoie à quel mot exactement ?
- Le contexte sémantique : “prêt” + “refusé” indiquent un contexte bancaire
- Les relations causales : “parce qu’” établit un lien de cause à effet
Mais voilà le problème : il ne peut pas tout analyser avec la même intensité en même temps. C’est comme essayer de regarder simultanément la forme d’un tableau, ses couleurs, sa composition et les détails de chaque coin avec un seul regard focalisé. Vous devez choisir où porter votre attention, et vous perdez nécessairement des informations.
Les phrases humaines sont des structures multidimensionnelles. Chaque mot entretient plusieurs types de relations avec les autres mots : syntaxiques (grammaire), sémantiques (sens), référentielles (pronoms), causales (logique). Pour vraiment “comprendre”, un modèle doit capturer toutes ces dimensions simultanément.
La Solution : 8 Projecteurs Qui Travaillent En Parallèle
L’attention multi-head résout ce problème avec une élégance remarquable : au lieu d’un seul mécanisme d’attention, le modèle en utilise plusieurs en parallèle. Dans GPT-2, ce sont 12 têtes (12 projecteurs). Dans GPT-3, jusqu’à 96. Chaque tête est un projecteur indépendant qui illumine la phrase à sa manière.
Prenons 8 têtes pour notre exemple. Voici comment elles pourraient se spécialiser sur notre phrase :
Projecteur 1 (syntaxe de base) : Éclaire intensément “La banque” → “a refusé”. Il capture la relation sujet-verbe immédiate. Son faisceau est concentré sur la structure grammaticale de base.
Projecteur 2 (objets et compléments) : Éclaire “refusé” → “mon prêt”. Il comprend que “prêt” est l’objet direct du refus. Son angle révèle ce qui subit l’action.
Projecteur 3 (résolution de pronoms) : Éclaire “elle” → “La banque”. C’est son expertise : il cherche systématiquement à qui ou à quoi renvoient les pronoms. Son faisceau fait le lien entre “elle” et son référent.
Projecteur 4 (contexte sémantique) : Éclaire un triangle entre “banque”, “prêt” et “refusé”. Il détecte le champ sémantique cohérent de la finance. Son éclairage large révèle le thème général.
Projecteur 5 (relations causales) : Éclaire “refusé” → “parce qu’” → “était prudente”. Il suit la logique cause-effet. Son faisceau trace les liens de raisonnement.
Projecteur 6 (attributs et qualités) : Éclaire “prudente” → “elle” (donc “banque”). Il comprend que “prudente” décrit une caractéristique de la banque. Son angle révèle les propriétés des entités.
Projecteur 7 (possession) : Éclaire “mon” → “prêt”. Il capture les relations de possession et d’appartenance. Son faisceau est spécialisé dans les déterminants possessifs.
Projecteur 8 (cohérence globale) : Éclaire l’ensemble de la phrase avec un faisceau large. Il vérifie que tous les éléments forment un tout cohérent.
Chaque projecteur (chaque tête d’attention) travaille indépendamment. Ils ne se consultent pas entre eux pendant leur analyse. C’est comme 8 experts dans une pièce, chacun prenant des notes sur sa spécialité, sans parler aux autres. Cette indépendance est cruciale : elle permet au modèle de traiter tous ces aspects en parallèle, simultanément.
Comment Les Faisceaux Se Combinent Pour Créer La Compréhension
Une fois que les 8 projecteurs ont terminé leur travail, le modèle doit fusionner toutes ces observations en une seule compréhension riche et nuancée.
Imaginons que chaque projecteur ait produit un rapport détaillé sur le mot “elle” :
- Projecteur 1 : “Sujet du verbe ‘était’, position syntaxique claire”
- Projecteur 2 : “Pas d’objet direct associé”
- Projecteur 3 : “Référence à ‘La banque’ avec 98% de confiance”
- Projecteur 4 : “Contexte financier maintenu, cohérent”
- Projecteur 5 : “Cause de l’action de refus”
- Projecteur 6 : “Possède l’attribut ‘prudente’”
- Projecteur 7 : “Pas de relation de possession”
- Projecteur 8 : “Cohérent avec le reste de la phrase”
Le modèle concatène (met bout à bout) tous ces rapports. Si chaque projecteur produit une représentation de 64 dimensions (64 nombres décrivant ce qu’il a vu), alors 8 projecteurs produisent 8 × 64 = 512 dimensions.
Cette représentation enrichie de “elle” contient maintenant toutes les nuances : sa fonction syntaxique, son référent, son rôle dans la causalité, ses attributs. C’est comme avoir une carte 3D haute résolution avec plusieurs couches d’information superposées, au lieu d’un simple croquis en 2D.
Cette fusion ne se fait pas au hasard. Le modèle apprend pendant son entraînement comment pondérer et harmoniser ces différentes perspectives. Certaines informations sont amplifiées, d’autres atténuées, selon ce qui est le plus utile pour comprendre le contexte ou prédire le mot suivant.
Pourquoi Plusieurs Projecteurs Valent Mieux Qu’Un Seul Très Puissant
Vous pourriez vous demander : pourquoi pas un seul projecteur ultra-puissant de 512 dimensions au lieu de 8 petits de 64 dimensions chacun ?
La réponse tient à la spécialisation et à l’efficacité de l’apprentissage.
Imaginez que vous deviez apprendre simultanément à jouer du piano, à peindre des portraits et à résoudre des équations différentielles. Votre cerveau essaierait de tout mélanger, et vous progresseriez lentement dans les trois domaines. Maintenant, imaginez trois personnes, chacune se concentrant exclusivement sur un domaine. Au final, l’équipe collective est bien plus compétente, et chaque membre devient un véritable expert.
C’est exactement ce qui se passe avec les têtes d’attention. Pendant l’entraînement du modèle sur des milliards de mots, chaque tête découvre spontanément qu’elle peut devenir meilleure en se spécialisant dans un type particulier de relation. Personne ne leur dit explicitement “Toi, tu t’occupes de la syntaxe, toi du sens”. Cette spécialisation émerge naturellement parce que c’est la stratégie la plus efficace pour minimiser l’erreur du modèle.
Des chercheurs ont analysé des modèles comme BERT et GPT après leur entraînement et ont découvert des spécialisations fascinantes :
- Certaines têtes se concentrent presque exclusivement sur les pronoms et leurs référents
- D’autres détectent les relations entre noms et adjectifs
- Certaines capturent les dépendances à longue distance (début et fin de phrase)
- D’autres encore se spécialisent dans les entités nommées (personnes, lieux, organisations)
Cette division du travail émergente est l’une des raisons principales pour lesquelles les transformers fonctionnent si remarquablement bien.
Le Parcours Complet D’Un Mot Sous Les Projecteurs
Suivons le mot “elle” du début à la fin de son voyage à travers l’attention multi-head :
Étape 1 : Préparation (l’encodage initial)
Le mot “elle” arrive avec sa représentation numérique initiale : un vecteur de 512 nombres qui encode sa position dans la phrase, son identité, et un peu de contexte de base. Pensez-y comme aux coordonnées GPS du mot dans l’espace multidimensionnel du langage.
Étape 2 : Multiplication des perspectives
Cette représentation unique est envoyée simultanément aux 8 têtes d’attention. C’est comme si vous preniez une photo et que vous la donniez à 8 photographes différents, chacun avec un filtre différent sur son appareil.
Chaque tête transforme cette représentation selon sa propre perspective. La tête spécialisée dans les pronoms va la transformer pour mieux détecter les référents. La tête syntaxique va la transformer pour mieux voir les relations grammaticales.
Étape 3 : Éclairage sélectif (le cœur de l’attention)
Maintenant vient la magie. Chaque tête regarde tous les autres mots de la phrase et décide lesquels sont importants pour comprendre “elle” dans son domaine de spécialité.
- Tête 3 (pronoms) décide : “La banque” est crucial (95% d’attention), “mon” est un peu utile (5%), le reste est négligeable.
- Tête 1 (syntaxe) décide : “était” est crucial (90%), “prudente” est utile (40%).
- Tête 5 (causalité) décide : “parce qu’” est crucial (85%), “refusé” est très utile (70%).
Chaque tête crée ainsi une carte d’attention : un ensemble de poids qui indiquent où elle a pointé son projecteur et avec quelle intensité.
Étape 4 : Création de la nouvelle représentation enrichie
En fonction de cette carte d’attention, chaque tête crée une nouvelle représentation de “elle” qui incorpore les informations des mots qu’elle a jugés importants.
La tête 3 produit une représentation de “elle” qui dit essentiellement : “Je suis un pronom féminin singulier qui fait référence à ‘La banque’.”
La tête 1 produit : “Je suis le sujet grammatical de ‘était’ et je suis associé à l’adjectif ‘prudente’.”
Et ainsi de suite pour les 8 têtes. Huit représentations différentes, huit perspectives complémentaires.
Étape 5 : Fusion et synthèse
Ces 8 représentations (8 × 64 = 512 dimensions) sont mises bout à bout comme des wagons d’un train. Cette longue représentation passe ensuite par une dernière transformation qui l’harmonise et la compresse si nécessaire.
Résultat final : “elle” a maintenant une représentation qui encode :
- Son référent exact (la banque)
- Sa fonction grammaticale (sujet)
- Son rôle dans la causalité (agent de la prudence)
- Ses attributs (prudente)
- Sa cohérence avec le contexte financier
Tout cela dans un seul vecteur de nombres, prêt à être utilisé pour la suite du traitement ou pour prédire le mot suivant.
Ce Que Vous Avez Compris
Vous savez maintenant comment ChatGPT peut comprendre simultanément tous les aspects d’une phrase complexe. L’attention multi-head, c’est :
- Plusieurs mécanismes d’attention en parallèle (les projecteurs), chacun avec son propre angle de vue
- Chacun se spécialise spontanément pendant l’entraînement dans un type de relation linguistique
- Tous travaillent simultanément, ce qui rend le traitement rapide et efficace
- Les résultats sont fusionnés pour créer une compréhension riche, multidimensionnelle et nuancée
La prochaine fois que vous discutez avec ChatGPT ou un autre LLM, imaginez ces multiples projecteurs (8, 12, ou même 96 selon le modèle) qui scannent chaque mot de votre phrase. Chacun cherche quelque chose de différent : l’un traque les pronoms, l’autre analyse la grammaire, un troisième détecte les relations logiques. Tous ensemble, ils créent cette impression de “compréhension” qui rend ces modèles si impressionnants.
Simplifications Pédagogiques : Ce Qu’Il Faut Savoir
J’ai volontairement simplifié plusieurs aspects techniques pour rendre le concept accessible à un débutant complet. Voici exactement ce qui a été simplifié et pourquoi c’est acceptable pour votre compréhension.
1. Les projections Query, Key, Value (QKV)
Ce que j’ai dit : Chaque tête “transforme la représentation selon sa propre perspective”.
La réalité technique : Chaque tête crée en fait trois versions différentes de chaque mot via des matrices de projection apprises :
- Query (requête) : ce que le mot cherche comme information
- Key (clé) : ce que le mot offre comme information aux autres
- Value (valeur) : l’information concrète que le mot transmet
L’attention se calcule en comparant la Query d’un mot avec les Keys de tous les autres mots. Les scores d’attention déterminent ensuite comment combiner les Values.
Pourquoi ma simplification est acceptable : Comprendre QKV nécessite des mathématiques matricielles (produits de matrices, transformations linéaires). L’idée essentielle reste vraie : chaque tête transforme les mots pour extraire certaines relations selon son angle spécifique. La métaphore du projecteur avec son “angle de vue” capture bien cette idée de transformation orientée, sans nécessiter les mathématiques sous-jacentes.
2. Le calcul d’attention (softmax et produit scalaire)
Ce que j’ai dit : Chaque tête “décide” quels mots sont importants et attribue des pourcentages d’attention (comme 95%, 5%).
La réalité technique : L’attention se calcule via :
- Un produit scalaire entre la Query du mot cible et les Keys de tous les mots
- Une division par √d (où d est la dimension) pour stabiliser les gradients
- Une fonction softmax qui transforme les scores en probabilités sommant exactement à 100%
La formule mathématique : Attention(Q, K, V) = softmax(QK^T / √d) V
Pourquoi ma simplification est acceptable : Le résultat final est bien un ensemble de poids (probabilités) indiquant l’importance relative de chaque mot. Que ces poids soient calculés via softmax ou par une autre méthode est moins important que le concept fondamental : certains mots reçoivent plus d’attention que d’autres, et ces poids déterminent comment l’information est combinée. Les pourcentages que j’ai donnés (95%, 5%) sont des exemples illustratifs du type de distribution que le softmax produit.
3. La spécialisation des têtes
Ce que j’ai dit : Chaque tête se spécialise clairement dans un type de relation précis (pronoms, syntaxe, causalité, etc.), avec des exemples très nets.
La réalité plus nuancée : La spécialisation des têtes est réelle mais souvent plus floue et moins catégorique que mes exemples. Une tête peut partiellement capturer plusieurs types de relations. De plus :
- La spécialisation varie selon les couches du modèle (les premières couches capturent des patterns plus simples, les dernières des relations plus abstraites)
- Certaines têtes semblent redondantes ou peu spécialisées
- La spécialisation n’est pas programmée mais émerge statistiquement de l’entraînement
Pourquoi ma simplification est acceptable : Des études scientifiques ont effectivement montré que des spécialisations émergent. Mes exemples sont des archétypes idéalisés qui aident à comprendre le principe. L’essentiel reste scientifiquement correct : avoir plusieurs têtes permet de capturer différents types de patterns linguistiques simultanément. J’aurais pu dire “une tête tend à se spécialiser partiellement dans…” mais cela aurait alourdi le texte sans ajouter à la compréhension conceptuelle pour un débutant.
4. Le nombre de têtes et les dimensions
Ce que j’ai dit : 8 têtes comme exemple principal, chacune produisant 64 dimensions (8 × 64 = 512).
La réalité variable : Le nombre de têtes et les dimensions varient énormément selon les modèles :
- GPT-2 small : 12 têtes, dimension totale 768 (donc 64 par tête)
- GPT-3 : 96 têtes, dimension totale 12,288 (donc 128 par tête)
- BERT-base : 12 têtes, dimension totale 768
- LLaMA 2 : varie selon la taille (32 à 64 têtes)
Le nombre de têtes est un hyperparamètre d’architecture choisi par les concepteurs.
Pourquoi ma simplification est acceptable : J’ai choisi 8 têtes et 64 dimensions parce que :
- 8 est assez grand pour montrer la diversité, pas trop pour perdre le lecteur
- 8 × 64 = 512 est un calcul simple qui illustre la concaténation
- Le principe reste identique quel que soit le nombre : plusieurs têtes en parallèle, concaténation des résultats
Les chiffres exacts importent peu pour comprendre le concept fondamental.
5. La fusion finale et la transformation de sortie
Ce que j’ai dit : Les 8 représentations sont “mises bout à bout” puis “harmonisées” par une transformation finale.
La réalité technique : Après la concaténation, il y a une multiplication par une matrice de poids W^O (la matrice de sortie). Cette matrice est elle aussi apprise pendant l’entraînement. Elle ne fait pas que “compresser” ou “harmoniser” : elle réorganise, réinterprète et combine l’information des différentes têtes de manière optimale pour la tâche.
Pourquoi ma simplification est acceptable : Le concept de concaténation suivie d’une transformation est correct. J’ai omis les détails mathématiques (multiplication matricielle, apprentissage des poids) parce qu’ils n’ajoutent pas à la compréhension conceptuelle pour un débutant. L’idée que “les informations sont fusionnées intelligemment” capture l’essentiel.
6. L’indépendance des têtes
Ce que j’ai dit : Les têtes travaillent “indépendamment” sans se consulter.
La nuance à ajouter : C’est vrai au sein d’une même couche : les têtes calculent leur attention en parallèle sans interaction directe. Mais dans un modèle profond avec de nombreuses couches empilées, les têtes d’une couche reçoivent les sorties des têtes de la couche précédente. Il y a donc une forme de collaboration indirecte à travers les couches.
Pourquoi ma simplification est acceptable : Pour comprendre le mécanisme multi-head, il suffit de comprendre que les têtes d’une même couche travaillent en parallèle. L’interaction entre couches est un niveau de complexité supplémentaire qui n’est pas nécessaire pour saisir le concept de base.
Ce qui reste rigoureusement exact
Malgré ces simplifications pédagogiques, ces points sont scientifiquement corrects :
✓ Les têtes multiples calculent leur attention en parallèle (vraiment simultané, pas séquentiel)
✓ Chaque tête calcule son attention indépendamment au sein de sa couche
✓ Les sorties sont concaténées puis transformées par une matrice apprise
✓ Les têtes développent des spécialisations pendant l’entraînement (même si c’est parfois flou)
✓ Ce mécanisme permet de capturer plusieurs types de relations simultanément
✓ C’est plus efficace qu’une seule tête de taille équivalente (prouvé empiriquement)
✓ Le nombre de têtes est un choix d’architecture important
Pour Aller Plus Loin : Questions Ouvertes
Maintenant que vous comprenez l’attention multi-head, voici quelques questions fascinantes que se posent les chercheurs :
Combien de têtes est vraiment optimal ? Trop peu et le modèle manque de nuances. Trop et elles deviennent redondantes, gaspillant de la mémoire et du calcul. Des études récentes montrent qu’on peut parfois supprimer 20-30% des têtes sans perte majeure de performance. Pourquoi certaines têtes semblent-elles inutiles ? Comment identifier les têtes critiques ?
Les têtes apprennent-elles vraiment des choses différentes ? Ou certaines font-elles des calculs redondants ? Des chercheurs ont créé des outils de visualisation (comme BertViz) qui montrent ce que chaque tête “regarde”. Parfois les patterns sont nets (une tête suit systématiquement les pronoms), parfois c’est plus mystérieux.
Peut-on contrôler ce qu’apprennent les têtes ? Au lieu de laisser la spécialisation émerger aléatoirement, pourrait-on forcer certaines têtes à se spécialiser dans des tâches précises ? Certains chercheurs expérimentent avec des “têtes guidées” pour améliorer les performances sur des tâches spécifiques.
Que se passe-t-il dans les couches profondes ? Les premières couches d’un modèle capturent des patterns simples (mots adjacents, syntaxe de base). Les dernières couches capturent des relations plus abstraites (inférences, raisonnement). Comment cette hiérarchie se construit-elle à travers les 24, 48 ou 96 couches d’un grand modèle ?
L’attention multi-head existe-t-elle dans le cerveau humain ? Notre système visuel utilise effectivement des “canaux” parallèles (forme, couleur, mouvement, profondeur) qui sont ensuite intégrés. Y a-t-il un parallèle avec le traitement du langage dans le cerveau ? Les neurosciences et l’IA peuvent-elles s’éclairer mutuellement ?
Ressources Web
- Understanding and Coding Self-Attention, Multi-Head Attention - Sebastian Raschka
- Tutorial on Transformers and Multi-Head Attention - UvA Deep Learning
- Transformer Explainer - Interactive Visualization
- The Illustrated Transformer - Jay Alammar
- Multi-Head Attention: Deep Dive - Dive into Deep Learning
- Attention Is All You Need - Paper original (2017)