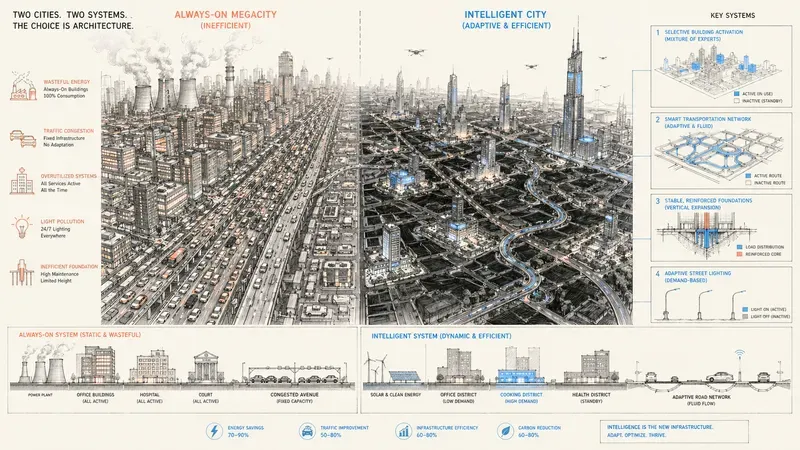
Résumé exécutif
Constat : DeepSeek V4 affiche une échelle spectaculaire, 1.6 trillion de paramètres et un contexte d’un million de tokens, mais son intérêt principal n’est pas la taille. C’est l’efficacité du système.
Thèse : V4 ne gagne pas seulement en ajoutant de la puissance. Il réduit le gaspillage : MoE n’active qu’une fraction du modèle, l’attention hybride évite de relire tout le contexte, mHC stabilise les flux profonds, Muon contrôle mieux la géométrie des poids, et FP4 réduit la mémoire nécessaire.
Point clé : le modèle devient une ville mieux conçue, pas seulement une ville plus grande. La performance vient de l’urbanisme interne : circulation, indexation, stabilité, compression et précision ciblée.
Pourquoi ça compte : si cette direction tient à grande échelle, la prochaine frontière des LLM ne sera pas seulement “plus de paramètres”, mais “moins de calcul inutile par token utile”.
Glossaire
- MoE (Mixture of Experts)
- : architecture où le modèle contient beaucoup d’experts, mais n’en active qu’une partie pour chaque token. La capacité totale augmente sans payer tout le coût à chaque inférence.
- Paramètres actifs
- : sous-ensemble des paramètres réellement utilisés pendant une passe d’inférence. Un modèle MoE peut avoir 1.6T de paramètres au total, mais n’en activer qu’une fraction.
- Contexte
- : quantité de tokens que le modèle peut prendre en compte dans une requête ou une conversation. V4 annonce un contexte natif d’un million de tokens.
- Attention
- : mécanisme qui permet au modèle de décider quelles parties du contexte sont importantes pour produire le prochain token.
- CSA (Compressed Sparse Attention)
- : attention compressée et sparse qui réduit la longueur effective du contexte, puis sélectionne les blocs utiles.
- HCA (Heavily Compressed Attention)
- : attention très compressée qui garde une vue globale du contexte sous forme compacte.
- KV cache
- : mémoire utilisée en inférence pour stocker les clés et valeurs déjà calculées par l’attention. Sur les longs contextes, c’est l’un des principaux coûts mémoire.
- mHC (Manifold-Constrained Hyper-Connections)
- : mécanisme qui remplace ou renforce les connexions résiduelles classiques avec plusieurs flux contrôlés, afin de stabiliser les signaux et les gradients dans les modèles profonds.
- Muon Optimizer
- : optimiseur qui agit sur les matrices de poids comme des objets géométriques, plutôt que de corriger seulement chaque paramètre indépendamment.
- FP4 / FP8
- : formats numériques à basse précision. Ils stockent les poids avec moins de bits pour réduire la mémoire et accélérer certaines opérations, au prix d’une précision plus faible mais contrôlée.
DeepSeek vient de sortir V4.
Sur le papier, c’est absurde. 1.6 trillion de paramètres. 1 million de tokens de contexte. Et pourtant, c’est moins cher à faire tourner que la génération précédente.
Normalement, ça ne devrait pas être possible.
Depuis des années, la règle semblait simple :
plus c’est gros, plus ça coûte.
DeepSeek vient de prouver l’inverse. Et ça change la règle du jeu.
Pour une fois, ce n’est pas seulement une histoire de benchmarks. C’est une histoire d’ingénierie système.
La métaphore la plus simple : une ville.
Un modèle classique, c’est une mégalopole qui consomme toujours plus : plus de routes, plus de voitures, plus d’électricité, plus de béton.
DeepSeek V4 ne construit pas une ville plus grande. Il change son urbanisme.
Et l’urbanisme commence par un héritage. Dès V3, DeepSeek avait posé le principe fondateur : c’est une ville où l’on n’ouvre que les bureaux dont on a besoin. Si vous posez une question sur la cuisine, le reste de la ville reste éteint. C’est le Mixture of Experts (MoE), et c’est ce qui explique qu’un modèle de 1.6 trillion de paramètres ne coûte pas comme un modèle dense équivalent : la ville est immense, mais à chaque instant, seule une fraction des bureaux est allumée.
V4 reprend cette ville et pousse l’optimisation plus loin.
Il remplace les avenues saturées par un réseau de circulation intelligent : c’est l’attention hybride. Il renforce les fondations pour monter plus haut sans que la structure vibre : c’est mHC. Il éteint les lampadaires dans les rues où personne ne passe : c’est le FP4.
Pas plus de puissance. Plus de discipline.
Inférence : arrêter de tout regarder
Les modèles sont déjà assez bons. Le problème, c’est qu’ils travaillent trop souvent comme des systèmes qui ne savent pas économiser leurs efforts.
Le vrai problème des modèles actuels n’est pas leur intelligence. C’est leur inefficacité.
Un Transformer classique, c’est un enquêteur qui, à chaque nouvelle question, ressort tout le dossier d’instruction : chaque page, chaque annexe, chaque pièce jointe, même si la réponse tient en trois paragraphes.
Sur un dossier de dix pages, ça passe. À un million de tokens, ce n’est plus un dossier. C’est un entrepôt d’archives. Et si l’enquêteur doit tout relire à chaque fois, l’enquête n’avance plus.
DeepSeek change l’hypothèse fondamentale :
- un modèle n’a pas besoin de tout voir ;
- il a besoin de retrouver ce qui compte ;
- pas tout voir, tout retrouver.
Une vision locale : chercher au lieu de relire
Première brique : transformer l’attention en moteur de recherche.
L’enquêteur commence par compresser l’historique. Chaque paquet de pages est résumé en une fiche. Ensuite, au lieu de tout relire, il consulte les fiches, identifie les zones utiles, et ne retourne que dans les rayons pertinents.
C’est la différence entre lire 10 000 pages de dossier à chaque objection, et savoir immédiatement quelles pièces appeler à la barre.
À l’échelle d’un million de tokens, c’est ce changement qui fait basculer le système.
Une vision globale : ne jamais être perdu
Mais chercher localement ne suffit pas.
Un bon enquêteur ne se contente pas de retrouver les bonnes pièces. Il doit aussi garder en tête l’affaire entière : les personnages, la chronologie, les tensions, les contradictions.
DeepSeek maintient une version ultra compressée de toute la séquence.
Pas le dossier complet. Plutôt la carte murale dans la salle d’enquête : les lieux, les relations, les grandes dates, les liens entre les éléments.
Elle ne contient pas tous les détails. Mais elle évite de se perdre.
L’élégance du système : alterner les deux
Le vrai tour de force n’est pas seulement de chercher. Et pas seulement de résumer.
C’est d’alterner les deux.
À chaque profondeur du réseau, le modèle peut passer de la loupe de l’enquêteur à la carte murale de l’affaire.
C’est exactement ce que nous faisons en lisant un texte difficile : on bloque, on revient en arrière, on reprend le plan, puis on replonge.
DeepSeek a transformé cette alternance en architecture.
Le modèle sait quand ouvrir le dossier complet. Il sait quand consulter l’index. Il sait quand regarder la carte.
Le résultat : voir plus en calculant moins
À l’échelle d’un million de tokens, cette discipline change tout.
Résultat :
- DeepSeek-V4-Pro consomme 27% des FLOPs d’inférence par token de DeepSeek-V3.2 dans le contexte 1M, soit environ 3,7x moins de calcul ;
- il utilise 10% du KV cache de DeepSeek-V3.2, soit 10x moins de mémoire de cache ;
- DeepSeek-V4-Flash descend encore plus bas : 10% des FLOPs et 7% du KV cache, soit environ 10x moins de calcul et 14x moins de KV cache.
Le long contexte cesse d’être un luxe théorique. Il devient une capacité exploitable.
Ce n’est pas “plus de puissance”. C’est moins de puissance gaspillée.
Le détail compte : les 10x de calcul correspondent à V4-Flash, pas à V4-Pro. Et les 50x ne décrivent pas le KV cache officiel de V4-Pro ; c’était une confusion possible avec des ratios de compression internes à l’attention, pas avec la mémoire réellement rapportée au niveau modèle.
Entraînement : rendre stable ce qui ne devrait pas l’être
Optimiser l’inférence est une moitié du problème.
L’autre moitié est plus dure :
entraîner un système aussi complexe sans qu’il diverge.
Ici, la bonne métaphore n’est plus celle de l’enquêteur. C’est celle d’un gratte-ciel.
Ajouter des couches à un modèle, c’est comme ajouter des étages à une tour. Au début, ça tient. Puis, à mesure que la structure grandit, les petites tensions deviennent dangereuses.
Une vibration négligeable au rez-de-chaussée peut devenir une oscillation massive au sommet.
mHC : repenser la circulation de l’information
Historiquement, dans un Transformer, l’information circule d’une couche à l’autre par une seule colonne porteuse : la connexion résiduelle classique, inchangée dans son principe depuis les premières grandes architectures profondes.
DeepSeek la remplace par une structure multi-piliers. Plusieurs flux d’information traversent le réseau en parallèle, mélangés à chaque couche par des matrices apprises. L’édifice devient plus expressif, plus flexible.
Mais plus on ajoute de piliers, plus le système peut devenir instable.
Le problème : quand le système s’emballe
Sans contrainte, ces flux parallèles peuvent se renforcer les uns les autres.
L’image la plus parlante : le Larsen.
Tu branches un micro trop près d’une enceinte. Le son sort. Le micro le reprend. L’enceinte le réamplifie. Le micro le reprend encore. En quelques secondes, le système ne transmet plus de musique. Il hurle.
Dans un réseau profond, les connexions multi-flux peuvent produire exactement le même phénomène. Le signal ne circule plus proprement. Il s’amplifie de couche en couche, de façon incontrôlée. DeepSeek a mesuré une amplification jusqu’à 3000x, et le training s’effondre.
Ce n’est pas un problème de réglage. C’est un problème structural.
La solution : contraindre plutôt que simplifier
DeepSeek aurait pu simplifier. Réduire les flux. Revenir à un pilier unique.
Ils font l’inverse.
Ils gardent la richesse du système, mais ajoutent un limiteur.
Pensez à une table de mixage. Tu peux monter une piste, baisser une autre, redistribuer les sources. Mais le volume total reste sous contrôle. Aucune piste ne peut saturer le mix.
C’est ce que fait mHC : chaque couche peut mélanger l’information entre les flux. Mais la quantité totale de signal est conservée, par construction mathématique. Le Larsen ne peut pas se produire.
Résultat : l’amplification passe de 3000x à 1.6x. Le training est stable. Les gradients sont lisses.
mHC n’est pas une optimisation de confort. C’est la pièce structurelle qui rend l’édifice constructible.
Sans elle, la profondeur de V4, la largeur des flux et la précision réduite deviennent beaucoup plus difficiles à tenir ensemble.
Muon Optimizer : réaligner le châssis
DeepSeek introduit aussi un changement côté optimisation.
L’optimiseur classique AdamW est element-wise : il ajuste chaque paramètre indépendamment, sans savoir qu’un poids vit à côté d’un autre dans une matrice. C’est comme régler chaque pneu séparément. Ça corrige des symptômes locaux, mais ça ne garantit rien sur l’alignement global du véhicule.
Muon est un optimiseur de niveau matriciel. Il traite chaque matrice de poids comme un objet géométrique entier, et cherche à maintenir de meilleures propriétés d’orthogonalité au fil de l’apprentissage. Ce n’est plus la pression des pneus. C’est l’alignement des essieux : la géométrie structurelle du système.
La différence est fondamentale : AdamW peut pousser une matrice dans une direction déséquilibrée sans le “savoir”. Muon, en agissant sur la structure matricielle globale, empêche ces dérives géométriques avant qu’elles ne s’accumulent.
Le système reste hybride : AdamW est conservé pour les composants où l’approche locale suffit, comme les embeddings ou certaines normalisations. Muon intervient sur les grandes matrices où la géométrie compte, c’est-à-dire l’essentiel du modèle.
FP4 : réduire la précision pour gagner en échelle
Dernier levier : la précision numérique.
Un fichier photo RAW conserve énormément d’information. C’est précis, riche, et lourd. Un JPEG perd des détails. Mais il est beaucoup plus léger. Et dans la plupart des cas, il reste parfaitement exploitable.
DeepSeek fait la même chose avec les poids de ses experts MoE : il les entraîne et les sert avec une précision très réduite, notamment FP4 pour les experts dans les modèles instruct. L’information perdue n’est pas celle qui comptait le plus.
Résultat : beaucoup moins de mémoire, plus de paramètres exploitables, meilleure efficacité globale.
Le principe est toujours le même :
réduire sans casser.
Le pattern DeepSeek
Ce qui frappe avec V4, ce n’est pas une innovation isolée. C’est une cohérence.
Chaque décision répond à une contrainte réelle :
- trop de mémoire → compression et sélection ;
- trop de calcul → attention sparse et hybride ;
- instabilité du training → connexions contraintes ;
- précision numérique trop coûteuse → FP4 ciblé.
Et chaque solution est locale. Ciblée. Pragmatique.
Soyons précis : certaines de ces briques viennent directement de la recherche DeepSeek. mHC est leur paper, l’architecture d’attention compressée prolonge le MLA qu’ils avaient introduit dès V2, et le design hybride CSA/HCA est nouveau dans V4. D’autres, comme l’attention sparse, la quantisation agressive ou les optimiseurs matriciels, circulent dans la littérature depuis des années, avec des contributions de Google, Meta, ByteDance et de dizaines de labos académiques.
Ce qui distingue V4, c’est la capacité à combiner recherche originale et idées existantes dans une architecture cohérente, à pousser l’implémentation jusqu’au kernel, et à mettre le tout en production à l’échelle 1.6T sous licence MIT.
C’est moins spectaculaire qu’un breakthrough unique. Mais c’est ce qui produit un modèle qu’on peut réellement utiliser.
DeepSeek ne cherche pas une idée géniale. Ils suppriment les inefficacités une par une.
Ce que ça dit vraiment
Pendant longtemps, scaler voulait dire : plus de GPU, plus de paramètres, plus de données.
V4 pose une question différente.
Une centrale électrique plus puissante peut alimenter une ville. Mais une ville mieux conçue peut consommer beaucoup moins pour le même niveau d’activité.
C’est la leçon de V4. Ce n’est pas plus de calcul. C’est moins de calcul inutile.
Conclusion
DeepSeek V4 n’est pas seulement un modèle plus gros.
C’est un modèle qui a appris à ne pas travailler inutilement.
Il ne relit pas tout. Il indexe. Il ne garde pas tout en mémoire. Il cartographie. Il ne laisse pas ses signaux s’emballer. Il les régule. Il ne corrige pas seulement des poids. Il réaligne des structures. Il ne conserve pas toute la précision possible. Il garde celle qui sert.
À l’échelle de l’IA moderne, c’est un signal faible, mais structurant. Parce que la course ne se jouera pas seulement sur les modèles capables de penser plus.
Elle se jouera aussi sur les systèmes capables de gaspiller moins.
DeepSeek V4 n’est pas une démonstration de puissance.
C’est une démonstration d’intégration système.
Ressources
DeepSeek V4
Fiche modèle Hugging Face : DeepSeek-V4-Pro
Présente les chiffres principaux : 1.6T paramètres, 49B actifs, contexte 1M, CSA/HCA, mHC, Muon, précision FP4/FP8, et efficacité long contexte officielle de V4-Pro : 27% des FLOPs par token et 10% du KV cache de V3.2.
Technical report
Rapport PDF : DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
Source des détails d’architecture et des comparaisons d’efficacité long contexte.
Analyse Hugging Face
Article : DeepSeek-V4: a million-token context that agents can actually use
Synthèse utile sur le KV cache, l’attention hybride, les chiffres V4-Pro/V4-Flash et les implications pour les agents.