Executive Summary
Observation: DeepSeek V4 has a spectacular scale, 1.6 trillion parameters and a one-million-token context window, but its main point is not size. It is system efficiency.
Thesis: V4 does not win only by adding power. It cuts waste: MoE activates only a fraction of the model, hybrid attention avoids rereading the entire context, mHC stabilizes deep signal flows, Muon controls weight geometry more directly, and FP4 reduces memory needs.
Key point: the model is a better-designed city, not just a larger one. Performance comes from its internal urban planning: routing, indexing, stability, compression, and targeted numerical precision.
Why it matters: if this direction holds at scale, the next frontier for LLMs will not be only “more parameters”, but “less useless compute per useful token”.
Glossary
- MoE (Mixture of Experts)
- : architecture where the model contains many experts, but activates only part of them for each token. Total capacity increases without paying the full cost at every inference step.
- Active parameters
- : subset of parameters actually used during an inference pass. A MoE model may contain 1.6T total parameters while activating only a fraction of them.
- Context
- : amount of tokens the model can take into account in a prompt or conversation. V4 announces a native one-million-token context window.
- Attention
- : mechanism that lets the model decide which parts of the context matter for producing the next token.
- CSA (Compressed Sparse Attention)
- : compressed and sparse attention that reduces the effective context length, then selects the useful blocks.
- HCA (Heavily Compressed Attention)
- : heavily compressed attention that keeps a global view of the context in compact form.
- KV cache
- : inference memory used to store keys and values already computed by attention. On long contexts, it is one of the main memory costs.
- mHC (Manifold-Constrained Hyper-Connections)
- : mechanism that replaces or strengthens classic residual connections with several controlled streams, stabilizing signals and gradients in deep models.
- Muon Optimizer
- : optimizer that acts on weight matrices as geometric objects, rather than correcting each parameter independently.
- FP4 / FP8
- : low-precision numerical formats. They store weights with fewer bits to reduce memory and speed up some operations, at the cost of lower but controlled precision.
DeepSeek has just released V4.
On paper, it sounds absurd. 1.6 trillion parameters. A one-million-token context window. And yet, it is cheaper to run than the previous generation.
Normally, this should not be possible.
For years, the rule seemed simple:
bigger means more expensive.
DeepSeek just proved the opposite. And that changes the game.
For once, this is not only a benchmark story. It is a story about systems engineering.
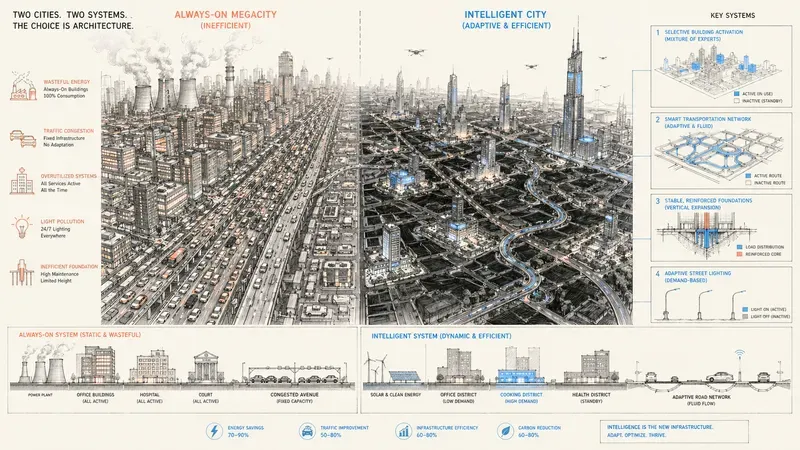
The simplest metaphor is a city.
A classic model is a megacity that keeps consuming more: more roads, more cars, more electricity, more concrete.
DeepSeek V4 does not build a larger city. It changes the urban plan.
And the urban plan begins with an inheritance. Since V3, DeepSeek had already set the founding principle: this is a city where only the offices you need are opened. If you ask a cooking question, the rest of the city stays dark. That is Mixture of Experts (MoE), and it explains why a 1.6 trillion parameter model does not cost as much as an equivalent dense model: the city is huge, but at any given moment only a fraction of its offices are lit.
V4 takes that city and pushes the optimization further.
It replaces congested avenues with an intelligent traffic network: hybrid attention. It reinforces the foundations so the tower can rise without shaking: mHC. It turns off streetlights where nobody is walking: FP4.
Not more power. More discipline.
Inference: stop looking at everything
Models are already good enough. The problem is that they too often behave like systems that do not know how to save effort.
The real problem with current models is not intelligence. It is inefficiency.
A classic Transformer is like an investigator who, for every new question, pulls the entire case file back onto the desk: every page, every appendix, every attachment, even if the answer fits in three paragraphs.
For a ten-page case file, that works. At one million tokens, it is no longer a file. It is a warehouse of archives. And if the investigator has to reread everything every time, the investigation stops moving.
DeepSeek changes the basic assumption:
- a model does not need to see everything;
- it needs to retrieve what matters;
- not see everything, retrieve everything that counts.
A local view: search instead of rereading
First building block: turn attention into a search engine.
The investigator starts by compressing the history. Each bundle of pages becomes a summary card. Then, instead of rereading everything, he checks the cards, identifies the useful zones, and goes back only to the relevant shelves.
That is the difference between reading 10,000 pages of a case file for every objection, and immediately knowing which pieces of evidence to call to the stand.
At the scale of one million tokens, this change is what makes the system flip.
A global view: never getting lost
But local search is not enough.
A good investigator does not only retrieve the right pieces. He also keeps the whole case in mind: the characters, the timeline, the tensions, the contradictions.
DeepSeek keeps an ultra-compressed version of the entire sequence.
Not the full file. More like the wall map in the investigation room: places, relationships, major dates, links between elements.
It does not contain every detail. But it prevents the model from getting lost.
The elegance of the system: alternating both
The real achievement is not only search. And not only summarization.
It is alternating both.
At each depth of the network, the model can move from the investigator’s magnifying glass to the case map on the wall.
That is exactly what we do when reading a difficult text: we get stuck, go back, recover the plan, then dive back into the details.
DeepSeek turned that alternation into architecture.
The model knows when to open the full file. It knows when to consult the index. It knows when to look at the map.
The result: seeing more while computing less
At the scale of one million tokens, this discipline changes everything.
Result:
- DeepSeek-V4-Pro uses 27% of DeepSeek-V3.2’s single-token inference FLOPs in the 1M-token setting, or about 3.7x less compute;
- it uses 10% of DeepSeek-V3.2’s KV cache, or 10x less cache memory;
- DeepSeek-V4-Flash goes lower: 10% of the FLOPs and 7% of the KV cache, or about 10x less compute and 14x less KV cache.
Long context stops being a theoretical luxury. It becomes a usable capability.
This is not “more power”. It is less wasted power.
The distinction matters: the 10x compute figure belongs to V4-Flash, not V4-Pro. And 50x does not describe V4-Pro’s official KV-cache reduction; that was likely a confusion with internal attention compression ratios, not with model-level memory reported by DeepSeek.
Training: stabilizing what should not be stable
Optimizing inference is half the problem.
The other half is harder:
training such a complex system without making it diverge.
Here, the right metaphor is no longer the investigator. It is a skyscraper.
Adding layers to a model is like adding floors to a tower. At first, it holds. Then, as the structure grows, tiny tensions become dangerous.
A negligible vibration on the ground floor can become a massive oscillation at the top.
mHC: rethinking information flow
Historically, in a Transformer, information flows from one layer to the next through a single load-bearing column: the classic residual connection, unchanged in principle since the first major deep architectures.
DeepSeek replaces it with a multi-pillar structure. Several information streams cross the network in parallel, mixed at each layer by learned matrices. The building becomes more expressive and more flexible.
But the more pillars you add, the more unstable the system can become.
The problem: when the system runs away
Without constraints, these parallel flows can reinforce one another.
The clearest image is audio feedback.
You put a microphone too close to a speaker. Sound comes out. The microphone captures it. The speaker amplifies it. The microphone captures it again. Within seconds, the system no longer transmits music. It screams.
In a deep network, multi-stream connections can create exactly the same phenomenon. The signal no longer flows cleanly. It amplifies from layer to layer in an uncontrolled way. DeepSeek measured amplification up to 3000x, and training collapses.
This is not a tuning issue. It is a structural issue.
The solution: constrain rather than simplify
DeepSeek could have simplified. Reduce the streams. Return to a single pillar.
They do the opposite.
They keep the richness of the system, but add a limiter.
Think of a mixing console. You can raise one track, lower another, redistribute sources. But the total volume stays under control. No track can saturate the mix.
That is what mHC does: each layer can mix information between streams. But the total amount of signal is preserved by mathematical construction. Feedback cannot happen.
Result: amplification falls from 3000x to 1.6x. Training is stable. Gradients are smooth.
mHC is not a comfort optimization. It is the structural piece that makes the building constructible.
Without it, V4’s depth, stream width, and reduced precision become much harder to hold together.
Muon Optimizer: realigning the chassis
DeepSeek also changes the optimization side.
The classic optimizer, AdamW, is element-wise: it adjusts each parameter independently, without knowing that a weight lives next to another weight inside a matrix. It is like adjusting each tire separately. It fixes local symptoms, but it does not guarantee the vehicle’s global alignment.
Muon is a matrix-level optimizer. It treats each weight matrix as a whole geometric object and tries to maintain better orthogonality properties during learning. This is no longer tire pressure. It is axle alignment: the structural geometry of the system.
The difference is fundamental: AdamW can push a matrix in an unbalanced direction without “knowing” it. Muon, by acting on the global matrix structure, prevents these geometric drifts before they accumulate.
The system remains hybrid: AdamW is kept for components where the local approach is enough, such as embeddings or some normalization layers. Muon intervenes on the large matrices where geometry matters, meaning most of the model.
FP4: reducing precision to gain scale
Last lever: numerical precision.
A RAW photo file preserves a huge amount of information. It is precise, rich, and heavy. A JPEG loses details. But it is much lighter. And in most cases, it remains perfectly usable.
DeepSeek does the same thing with the weights of its MoE experts: it trains and serves them with very low precision, notably FP4 for experts in instruct models. The information that is lost is not the information that mattered most.
Result: much less memory, more usable parameters, better overall efficiency.
The principle is always the same:
reduce without breaking.
The DeepSeek pattern
What stands out with V4 is not an isolated innovation. It is coherence.
Every decision answers a real constraint:
- too much memory -> compression and selection;
- too much compute -> sparse and hybrid attention;
- training instability -> constrained connections;
- numerical precision too expensive -> targeted FP4.
And every solution is local. Targeted. Pragmatic.
Let us be precise: some of these building blocks come directly from DeepSeek research. mHC is their paper, the compressed attention architecture extends MLA, which they introduced back in V2, and the hybrid CSA/HCA design is new in V4. Others, such as sparse attention, aggressive quantization, or matrix-level optimizers, have circulated in the literature for years, with contributions from Google, Meta, ByteDance, and dozens of academic labs.
What distinguishes V4 is the ability to combine original research and existing ideas into a coherent architecture, push implementation down to the kernel level, and ship it at 1.6T scale under the MIT license.
That is less spectacular than a single breakthrough. But it is what produces a model you can actually use.
DeepSeek is not looking for one brilliant idea. They remove inefficiencies one by one.
What this really says
For a long time, scaling meant: more GPUs, more parameters, more data.
V4 asks a different question.
A more powerful power plant can supply a city. But a better-designed city can consume much less for the same level of activity.
That is the lesson of V4. It is not more compute. It is less useless compute.
Conclusion
DeepSeek V4 is not only a bigger model.
It is a model that has learned not to work unnecessarily.
It does not reread everything. It indexes. It does not keep everything in memory. It maps. It does not let signals run away. It regulates them. It does not only correct weights. It realigns structures. It does not preserve every bit of possible precision. It keeps the precision that matters.
At the scale of modern AI, this is a weak signal, but a structural one. Because the race will not only be won by models capable of thinking more.
It will also be won by systems capable of wasting less.
DeepSeek V4 is not a demonstration of power.
It is a demonstration of systems integration.
Resources
DeepSeek V4
Hugging Face model card: DeepSeek-V4-Pro
Presents the main figures: 1.6T parameters, 49B active parameters, 1M context, CSA/HCA, mHC, Muon, FP4/FP8 precision, and V4-Pro’s official long-context efficiency: 27% single-token FLOPs and 10% KV cache compared with V3.2.
Technical report
PDF report: DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
Source for architecture details and long-context efficiency comparisons.
Hugging Face analysis
Article: DeepSeek-V4: a million-token context that agents can actually use
Useful synthesis on KV cache, hybrid attention, V4-Pro/V4-Flash numbers, and implications for agents.